Tutorials for PU BS Students")






Understanding the Basics
In today’s data-driven world, Machine Learning (ML) has emerged as a powerful tool that enables computers to learn from data and improve their performance over time without being explicitly programmed. This article serves as a beginner’s guide to understanding the fundamentals of Machine Learning, its applications, and key concepts.
What is Machine Learning?
Machine Learning is a subset of artificial intelligence (AI) that focuses on the development of algorithms that allow computers to learn and make predictions or decisions based on data. Unlike traditional programming where explicit instructions are provided, in Machine Learning, the computer learns patterns and relationships from the data to perform tasks.
Types of Machine Learning
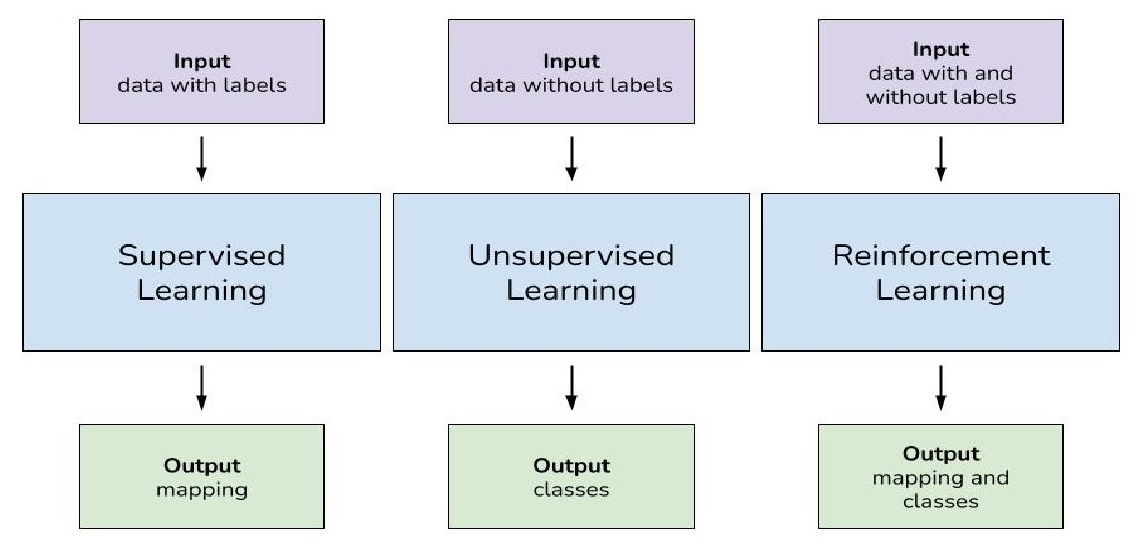
Machine Learning algorithms can be broadly categorized into three types:
Supervised Learning:
In supervised learning, the algorithm learns from labeled data, where each input is associated with a corresponding output. The goal is to learn a mapping function that accurately predicts the output for new, unseen inputs. Common supervised learning tasks include classification and regression.
– Classification: Classification involves predicting the category or class label of new observations based on past observations with known labels. For example, email spam detection or image classification.
– Regression: Regression predicts a continuous value or quantity based on input features. For instance, predicting house prices based on factors like area, location, and number of bedrooms.
Unsupervised Learning:
Unsupervised learning deals with unlabeled data, where the algorithm tries to find hidden patterns or structures within the data. Unlike supervised learning, there are no explicit output labels to guide the learning process. Clustering and dimensionality reduction are common unsupervised learning tasks.
– Clustering: Clustering algorithms group similar data points together based on their intrinsic properties. It is useful for tasks such as customer segmentation or image segmentation.
– Dimensionality Reduction: Dimensionality reduction techniques aim to reduce the number of input variables or features while preserving the essential information. Principal Component Analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE) are popular dimensionality reduction methods.
Reinforcement Learning:
Reinforcement learning involves an agent learning to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or penalties based on its actions, and the goal is to learn the optimal policy that maximizes cumulative reward over time. Applications of reinforcement learning include game playing, robotics, and autonomous vehicle control.
Key Concepts in Machine Learning
To grasp the principles of Machine Learning, it’s essential to understand some key concepts:
- Feature: Features are individual measurable properties or characteristics of the data that are used as input to the Machine Learning algorithm. For example, in a dataset of house prices, features could include area, number of bedrooms, and location.
- Model: A model is a mathematical representation of the relationship between the input features and the output. During the training phase, the model learns from the data to make predictions. Common types of models include decision trees, neural networks, and support vector machines.
- Training: Training refers to the process of feeding data into the model to adjust its parameters or weights so that it can learn to make accurate predictions. The training data is typically divided into training and validation sets, and the model’s performance is evaluated on the validation set to prevent overfitting.
- Evaluation: Evaluation involves assessing the performance of the trained model on unseen data. Common evaluation metrics include accuracy, precision, recall, and F1-score for classification tasks, and Mean Squared Error (MSE) or Root Mean Squared Error (RMSE) for regression tasks.
- Overfitting and Underfitting: Overfitting occurs when the model learns to capture noise or irrelevant patterns from the training data, leading to poor generalization on unseen data. Underfitting, on the other hand, occurs when the model is too simple to capture the underlying structure of the data. Balancing between the two is crucial for building robust Machine Learning models.
Applications of Machine Learning
Machine Learning has a wide range of applications across various domains, including:
– Healthcare: Predictive analytics for disease diagnosis, personalized treatment recommendations, and medical image analysis.
– Finance: Fraud detection, credit scoring, algorithmic trading, and risk management.
– E-commerce: Product recommendation systems, customer churn prediction, and sales forecasting.
– Natural Language Processing (NLP): Sentiment analysis, chatbots, language translation, and text summarization.
– Autonomous Vehicles: Object detection, path planning, and decision making for self-driving cars.
– Manufacturing: Predictive maintenance, quality control, and supply chain optimization.
– Entertainment: Content recommendation, personalized playlists, and user behavior analysis.
Machine Learning has revolutionized the way we process and analyze data, enabling computers to perform complex tasks that were once thought to be exclusive to human intelligence. As you delve deeper into the world of Machine Learning, remember that it’s not just about building predictive models but also about understanding the underlying principles and applying them creatively to solve real-world problems. With continuous learning and experimentation, the possibilities of Machine Learning are limitless.