 Tutorials for PU BS Students")





Before going to topic, First of all I would like to explain that what is an algorithm? An algorithm is a step-by-step set of instructions or procedures for solving a particular problem or accomplishing a specific task. It is a well-defined computational procedure that takes input, performs operations on that input, and produces output. Algorithms can be implemented using various programming languages and can range from simple to highly complex, depending on the problem they are designed to solve. Algorithms are essential in computer science and play a crucial role in fields such as data processing, artificial intelligence, cryptography, and optimization. They are used to automate tasks, make decisions, analyze data, and solve problems efficiently.
I think, now you are much familiar about algorithm, Now here are the characteristics of an algorithm include:
- Well-defined: An algorithm should have precise and unambiguous instructions, clearly defining the sequence of steps to be followed to solve a problem or accomplish a task.
- Finite: An algorithm must terminate after a finite number of steps. It should not run indefinitely or enter into an infinite loop.
- Input: An algorithm takes zero or more inputs, which are the data or information on which it operates to produce the desired output.
- Output: An algorithm produces one or more outputs, which are the results or solutions obtained after executing the algorithm on the given inputs.
- Definiteness: Each step of an algorithm must be precisely defined and executable. There should be no ambiguity or uncertainty in interpreting the instructions.
- Feasibility: An algorithm should be practical and feasible to implement using available computational resources within a reasonable amount of time and space.
- Correctness: An algorithm should produce the correct output for all valid inputs, accurately solving the problem it is designed for.
- Efficiency: An algorithm should be efficient in terms of time and space complexity. It should execute in a reasonable amount of time and use minimal resources to solve the problem efficiently.
- Deterministic: An algorithm should produce the same output for the same input every time it is executed. It should not rely on random or unpredictable behavior.
- Modularity: An algorithm should be modular, with well-defined subroutines or functions that can be reused or combined to solve related problems.
- Generality: An algorithm should be generalizable to handle various instances of the problem it is designed to solve. It should not be limited to specific inputs or scenarios.
- Robustness: An algorithm should be robust and able to handle unexpected or erroneous inputs gracefully, without crashing or producing incorrect results.
Now, here you will come to know about the types of machine learning algorithms.
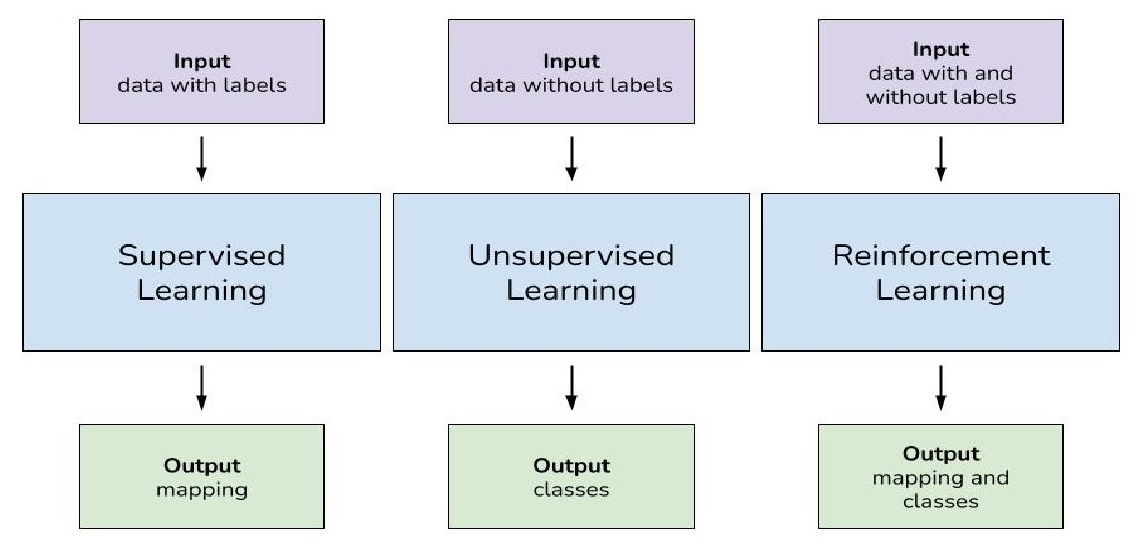
Supervised Learning
Supervised learning is a type of machine learning where the algorithm learns from labeled data, meaning each input is associated with a corresponding output. The goal is for the algorithm to learn a mapping or relationship between the input features and the output labels so that it can make predictions or decisions when presented with new, unseen data.
Linear Regression
Linear regression is a fundamental algorithm used in supervised learning for predicting continuous values based on input features. It models the relationship between the independent variables (features) and the dependent variable (target) by fitting a linear equation to the observed data. The goal is to find the line that best fits the data points, minimizing the difference between the predicted and actual values. For example, linear regression can be applied to predict house prices based on features like area, number of bedrooms, and location.
Logistic Regression
Unlike linear regression, logistic regression is used for binary classification tasks where the output variable takes two possible values (e.g., yes or no, spam or not spam). It models the probability of an input belonging to a particular class using the logistic function, which maps the input space to values between 0 and 1. Logistic regression is widely used in various applications, such as email spam detection, disease diagnosis, and credit risk assessment.
Decision Trees
Decision trees are non-linear models that recursively partition the feature space into regions, where each internal node represents a decision based on a feature. The tree structure is composed of nodes (representing features), edges (representing decisions), and leaves (representing outcomes). Decision trees are intuitive and easy to interpret, making them suitable for tasks where understanding the decision-making process is important. For example, decision trees can be used for classifying Iris flowers based on petal and sepal measurements.
Unsupervised Learning
Unsupervised learning is a type of machine learning where the algorithm learns from unlabeled data, meaning there are no explicit output labels provided. The goal of unsupervised learning is to discover hidden patterns, structures, or relationships within the data without any guidance or supervision.
K-Means Clustering
K-means clustering is a popular unsupervised learning algorithm used for grouping similar data points into clusters. It partitions the data into K clusters, where each cluster is represented by its centroid. The algorithm iteratively assigns each data point to the nearest centroid and updates the centroids based on the mean of the data points assigned to each cluster. K-means clustering is widely used for tasks such as customer segmentation, image compression, and anomaly detection.
Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is a dimensionality reduction technique used to reduce the number of features in a dataset while preserving its variance. It identifies the orthogonal directions of maximum variance, known as principal components, and projects the data onto these components. PCA is particularly useful for visualizing high-dimensional data and removing redundant or noisy features. For example, PCA can be applied to visualize the underlying structure of gene expression data.
Hierarchical Clustering
Hierarchical clustering is a clustering algorithm that builds a hierarchy of clusters by recursively merging or splitting them based on the similarity between data points. Unlike K-means clustering, hierarchical clustering does not require the number of clusters as input, making it suitable for datasets where the number of clusters is unknown. The result of hierarchical clustering can be visualized using a dendrogram, which represents the hierarchical structure of the clusters. Hierarchical clustering is commonly used in biology for clustering gene expression data and in document clustering for organizing text documents.
Reinforcement Learning
Reinforcement learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent learns to achieve a goal by taking actions in an environment and receiving feedback in the form of rewards or penalties. The goal of reinforcement learning is to learn the optimal policy, which is a mapping from states to actions, that maximizes the cumulative reward over time.
Q-Learning
Q-learning is a model-free reinforcement learning algorithm used for learning optimal policies in Markov decision processes (MDPs). It learns from experiences (states, actions, rewards) by updating the Q-values, which represent the expected cumulative reward of taking a particular action in a given state. Q-learning employs an exploration-exploitation strategy to balance between exploring new actions and exploiting the learned knowledge. For example, Q-learning can be used to train an agent to play simple games like Tic-Tac-Toe or navigate in a grid-world environment.
Deep Q-Network (DQN)
Deep Q-Network (DQN) is a deep reinforcement learning algorithm that combines Q-learning with deep neural networks to handle high-dimensional state spaces. It uses a neural network to approximate the Q-values, allowing it to learn complex decision-making policies directly from raw sensory input. DQN employs techniques like experience replay and target networks to stabilize training and improve sample efficiency. For example, DQN has been successfully applied to train agents to play Atari games using only pixel inputs.
Policy Gradient Methods
Policy gradient methods are a class of reinforcement learning algorithms that directly learn the policy function, which maps states to actions, without explicitly computing the value function. They update the policy parameters based on the performance of the policy, typically using gradient ascent methods. Policy gradient methods are suitable for problems with continuous action spaces or where the optimal policy is stochastic. For example, policy gradient methods can be used to train a robot to perform complex tasks in a simulated environment or to learn to play games like Go or Poker.
